

Chapters
Oxla is a scalable and flexible OLAP database that changes the data processing industry. Read about the development process, Oxla migrator tool, and our challenges.
In today's data-driven world, the ability to efficiently analyze and manage large datasets is crucial for businesses and organizations. This is where Oxla, a revolutionary OLAP database, and the Oxla Migrator tool, come into play, offering a solution for database automated integration and migration.
Understanding Oxla
What is Oxla?
At its core, Oxla is an OLAP (Online Analytical Processing) database. This means it's designed for complex data analysis rather than simple transaction processing. While you can insert and query data like any other OLAP database, Oxla stands out for several reasons. It supports the PostgreSQL wire protocol and a subset of PostgreSQL syntax, making it accessible to a wide range of users.
Oxla is more than just an analytical database; it's a step towards the data solution that its creators always wanted. With its imminent public tech preview, Oxla is set to make a significant impact in the data analytics space. For anyone involved in data analysis, Oxla represents an exciting, efficient, and user-friendly platform that promises to address long-standing challenges in the field.
Benefits of Oxla
- Efficiency: Analytical queries run significantly faster on Oxla compared to other solutions. It's not limited to specific types of queries or data sizes. Whether it's simple queries on small datasets or complex analysis on large data volumes, Oxla handles it all efficiently.
- Flexibility: The platform is designed to handle various operations like "group by" or "join" depending on the data size and distribution. The best part? This happens seamlessly, without requiring user intervention. This translates to fewer servers needed, increased productivity, and a versatile solution for both real-time and offline analysis.
- Scalability: Oxla features a cloud-focused architecture that decouples storage and computing. This design enables easy scalability and the use of cost-effective and reliable storage solutions. Starting with S3 and potentially expanding to other options, Oxla is geared for both cloud and on-premise deployments.
- Accessibility: Communicating using the PostgreSQL protocol and SQL dialect means widespread accessibility. Most programming languages can interact with Oxla, making the transition smoother for those already familiar with PostgreSQL. Efforts are underway to emulate more PostgreSQL internals to support advanced tools like Tableau or SQLAlchemy).

The Oxla Migrator
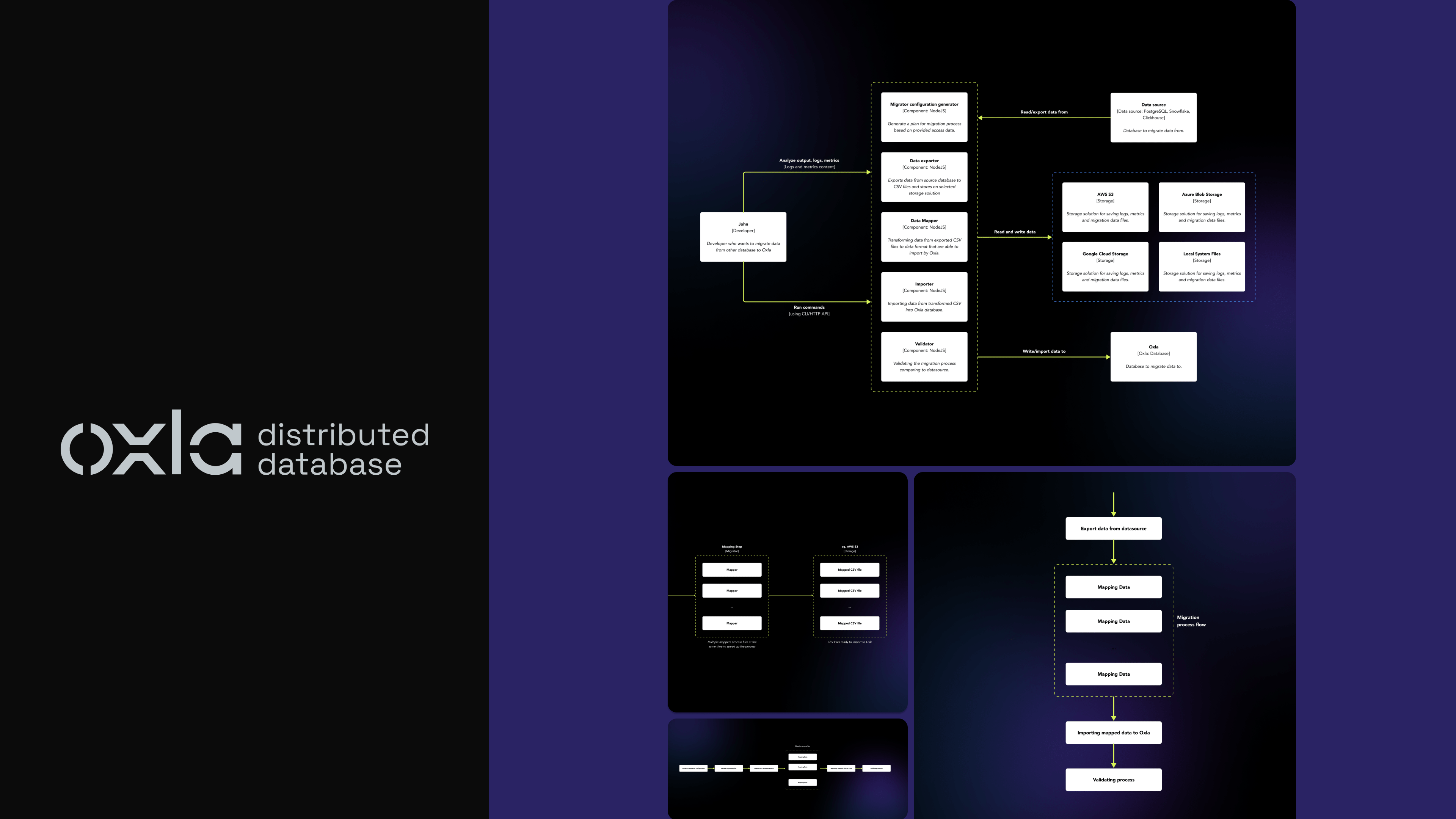
The Oxla Migrator is a bridge helping clients smoothly transition from existing databases to Oxla. It addresses the challenges of migrating large datasets, ensuring data integrity, and maintaining consistent performance.
Developing the Migrator: Challenges
- Schema Differences: Different databases often have varying schemas. The migration tool must be capable of interpreting and mapping different data structures, types, and constraints from Database A to B. This can be particularly challenging if the databases use different data models
- Data Volume and Performance: Large volumes of data can significantly impact the performance of the migration process. The tool must be efficient in handling and transferring large datasets without causing significant downtime or performance degradation.
- Data Integrity and Consistency: Ensuring data integrity during the migration process is critical. The tool must accurately migrate data without loss or corruption. Additionally, maintaining data consistency, especially in cases of incremental migrations where the source database is still in use, is challenging.
- Error Handling and Rollback: The tool should be able to handle errors gracefully and provide options to rollback changes in case of failure, to prevent data loss or corruption.
- Documentation: Comprehensive documentation is essential for guiding users through the migration process
Migration Configuration
When dealing with migration data from database A to database B it's common that database A will have type X but database B may not. In that case, we need some place to store all the tables with types of database A and what we will do with them when migrating to database B. In our case, we solved that problem by generating migration_config.json.
The migration_config.json is a vital component in managing the transition of types and values from one database to another. It is generated based on the schema of the data source database, ensuring a customized migration process.
Dumping and Mapping Data
- Efficient Data Handling: Utilizing streaming for efficient data processing. Instead of loading the entire dataset into memory, which can be inefficient and resource-intensive, the tool likely utilizes streaming. This approach processes data in chunks, reducing memory usage and improving performance.
- Type Mapping: Converting data to compatible types for Oxla using a CSV format. We need to have data in CSV format to map data to the correct types and values based on migration_config. First, we send queries to database A then we write that response to a CSV file.
Migration Process
- Data Loading: Efficiently creates tables with the correct schema and imports data using the COPY FROM statement. After the correct data dump & mapping, we should proceed with the migration of the whole data. First, we create tables and ensure that they have the current schema. Then we load data into those tables by COPY FROM statement.
- Concurrency: Implements a promise queue for simultaneous data imports. Instead of waiting for every query to complete we created a simple promise queue so we can execute multiple data imports simultaneously.
Validation and Monitoring
- Validation: Ensures data integrity by comparing row counts post-migration. To validate if the whole migration is completed we use a simple algorithm that counts table rows in the data source and in the table migrated to Oxla and compares them. If the number is not equal then the migrated table is invalid.
- Metrics and Logging: Utilizes custom solutions for performance monitoring and issue identification. Metrics and logs are crucial for monitoring the migration process, identifying issues, and ensuring data integrity. They provide transparency and accountability. Additionally, they were efficient for measuring performance since they included the name of the stage like generate config, create dump, and timestamp. To achieve that, we just created simple package metrics that added entries to the local SQLite database similar to logging.
The value of metrics and logging in each step that happens in code is huge specifically in debugging it and also in measuring performance or by creating nice visual graphs. It is worth mentioning that we adjusted the interface of created metrics to work with Prometheus and Grafana.
System Architecture
- Dependency Management: Utilizes `Nx` with `pnpm workspaces` for effective monorepo management.
- Data Transformation: Employs the `CSV` package for parsing and transforming CSV data.
- Independent Binaries: Creates standalone binaries for each migrator using the `pkg` package.
- REST API Integration: Uses Nest.js for a modular and integrated REST API setup. Our architecture was modular so we could use components for different migration tasks with ease, and easily integrate it in our REST API.
Docker
It’s worth mentioning that we did use docker images since there are many benefits like isolation, scalability, and portability. In our Docker setup, we use multi-stage builds to create lightweight images. Some of the worth-mentioning highlights from our Dockerfile configurations are:
- Multi-Stage Builds: We utilize multi-stage builds to keep our images as small as possible. The first stage includes all the tools needed to build the migrator, while the final image only contains the compiled binary and runtime essentials.
- Environment Variables and Entrypoints: We leverage environment variables and entrypoints to make our containers flexible and easy to configure at runtime.
Testing
Testing the Oxla Migrator was a formidable challenge, primarily due to the complexities inherent in data migration. The testing included:
- Data Variability: each dataset has its unique characteristics, requiring our tests to be adaptable to varying schemas, data types, and volumes.
- Data sets: For testing, we created scripts that populated each database type with a table of all possible types for each database that the migrator supports. So thanks to that we had datasets to test to be sure that migration of all types and values was correct.
- Performance Benchmarks: Establishing performance benchmarks and then testing against them was challenging, especially since migrations can be influenced by network latency, disk I/O, and other system-specific factors like differences between cloud solutions.
- Error Simulation: It was crucial to not only test for success cases but also to simulate various error conditions to ensure robust error handling and recovery mechanisms were in place.
- Continuous Integration (CI) Pipeline Complexity: Integrating our comprehensive testing suite into the CI pipeline was complex. We had to ensure that it did not excessively prolong the development cycle or consume excessive resources.
Migration process

Summing up
The Oxla Migrator Tool represents a significant advancement in database migration and integration. With its efficient, flexible, and developer-friendly configuration, it is poised to change how companies handle large-scale data migration. Incorporating Docker images further enhances the usability and deployment flexibility of the Oxla Migrator Tool, making it a comprehensive solution for modern data management needs.
Check out also:
- Web Accessibility - How to Design Websites and Write Code for Everyone - Learn about what web accessibility is, why it's important, and how to design and code websites that can be used by everyone.
- Ruby on Rails vs Node.js - What Tech to Choose in 2023 - The effects of some choices can drag on for years. Software developers, no matter their experience level, know this problem perfectly.
You may also like

Native vs Cross-Platform App Development: Which is Right for Your Business
3 September 2024 • Maria Pradiuszyk


We’re available for new projects.
